
 MENU
MENU FINE: Information embedding for document classification
Kevin M. Carter, Raviv Raich, Alfred O. Hero III
Abstract
The problem of document classification considers categorizing or grouping of various document types. Each document can be represented as a ‘bag of words’, which has no straightforward Euclidean representation. Relative word counts form the basis for similarity metrics among documents. Endowing the vector of term frequencies with a Euclidean metric has no obvious straightforward justification. A more appropriate assumption commonly used is that the data lies on a statistical manifold, or a manifold of probabilistic generative models. In this paper, we propose calculating a low-dimensional, information based embedding of documents into Euclidean space. One component of our approach motivated by information geometry is the Fisher information distance to define similarities between documents. The other component is the calculation of the Fisher metric over a lower dimensional statistical manifold estimated in a nonparametric fashion from the data. We demonstrate that in the classification task, this information driven embedding outperforms both a standard PCA embedding and other Euclidean embeddings of the term frequency vector.
Paper
Kevin M. Carter, Raviv Raich, and Alfred O. Hero III, “FINE: Information embedding for document classification,” Proc. of 2008 IEEE International Conference on Acoustics, Speech, and Signal Processing, Las Vegas, NV., March 2008, to appear. (.pdf)
Matlab Code
(.zip) This code requires the LibSVM package.
Figures
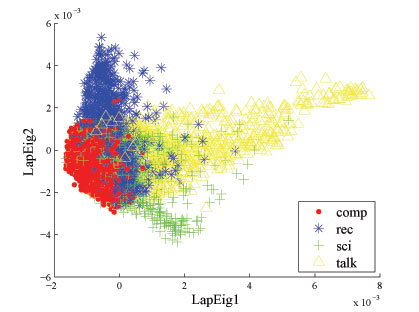
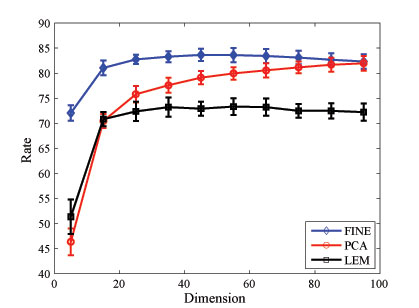
Figure 1. 2D embedding of document corpus using FINE. There is a clear natural separation shown between the different document classes although the method is unsupervised.Figure 2. 2D embedding of document corpus using PCA. There is no natural separation exhibited.Figure 3. Classification rates for low-dimensional embedding of document corpus, comparing different methods for dimensionality reduction (FINE, PCA, and LEM)
{kind=link}
{kind=link}
{kind=link}